I had recently researched a bit on the inner-working of the new emoji skin tone modifiers1 in Unicode 7.0.2 The basics: if a emoji skin tone modifier immediately follows certain characters they should be rendered as a single glyph.
“Combining characters; in conjunction with the preceding
character these indicate a predetermined choice of variant
glyph”
— Unicode Consortium U+FE00 code chart
The basic functionality of variation selectors are comparable to the emoji skin tone modifiers in that they choose a certain variation of the preceding character.
Currently only VS-1, VS15 and VS16 have been defined and implemented, check out a list of VS-1 variant glyphs.
Result on OS X 10.10.3: Chrome 42 and Safari 8.0.5 - the result on iOS with MobileSafari was identical to Safari. 3
I’ve used the Unicode converter on rishida.net quite a lot to convert to/from different Unicode representations. Taking another look at the solution by Jason and running it through the converter we see that the ↩ vs ↩︎ corresponds to: U+21A9 vs U+21A9U+FE0E - notice the U+FE0E at the end of the converted string.
If you’ve ever run gem install, you know how long it can take to complete. Trust me, you’re not alone: plentyofexamples showcase similar frustrations in dealing with slow gem install.
Most larger Ruby projects comes with extensive documentation (awesome! 👍), unfortunately the process of turning RDoc into HTML and ri can be quite time-consuming - especially on larger projects or slower machines.
Fortunately, it’s possible to turn off ri and rdoc processing on gem install by executing the command with flags --no-ri and --no-rdoc:
$ gem install rails --no-rdoc--no-ri
Now keep in mind that RDoc and ri is actually pretty cool and if you use them often, instead of online documentation, then you might want to skip this.
If you want this as your default behavior add this to your ~/.gemrc file:
gem: --no-ri--no-rdoc
Another option is to create a Shell alias for gem install that in addition also prefixes with sudo to avoid those pesky “You don’t have write permissions …“:
# Alias$ alias gemi=”sudo gem install –no-ri –no-rdoc”
# Usage$ gemi rails
In a recent project I wanted to use the new fetch API, if you are not familiar with the background story go read Jack Archibald’s “That’s so fetch!” post.
The overall browser support is starting to pick up, with Chrome 42(beta), Firefox 39 and Opera 29 all shipping with it by default. Internet Explorer is currently listing it as “under consideration” on their platform status page.
Luckily for us GitHub has been maintaining a great polyfill github/fetch since October 2014, which means we can already use this in production. Using the polyfill without a bundler like webpack would mean adding a <script> tag to your template.
I couldn’t figure out the “webpack way” of including the polyfill in my bundle, and after reading the webpack wiki page on shimming modules I still couldn’t quite figure out the syntax.
That was until I stumbled upon this gist by Luís Couto, showing exactly how to use the fetch polyfill with webpack.
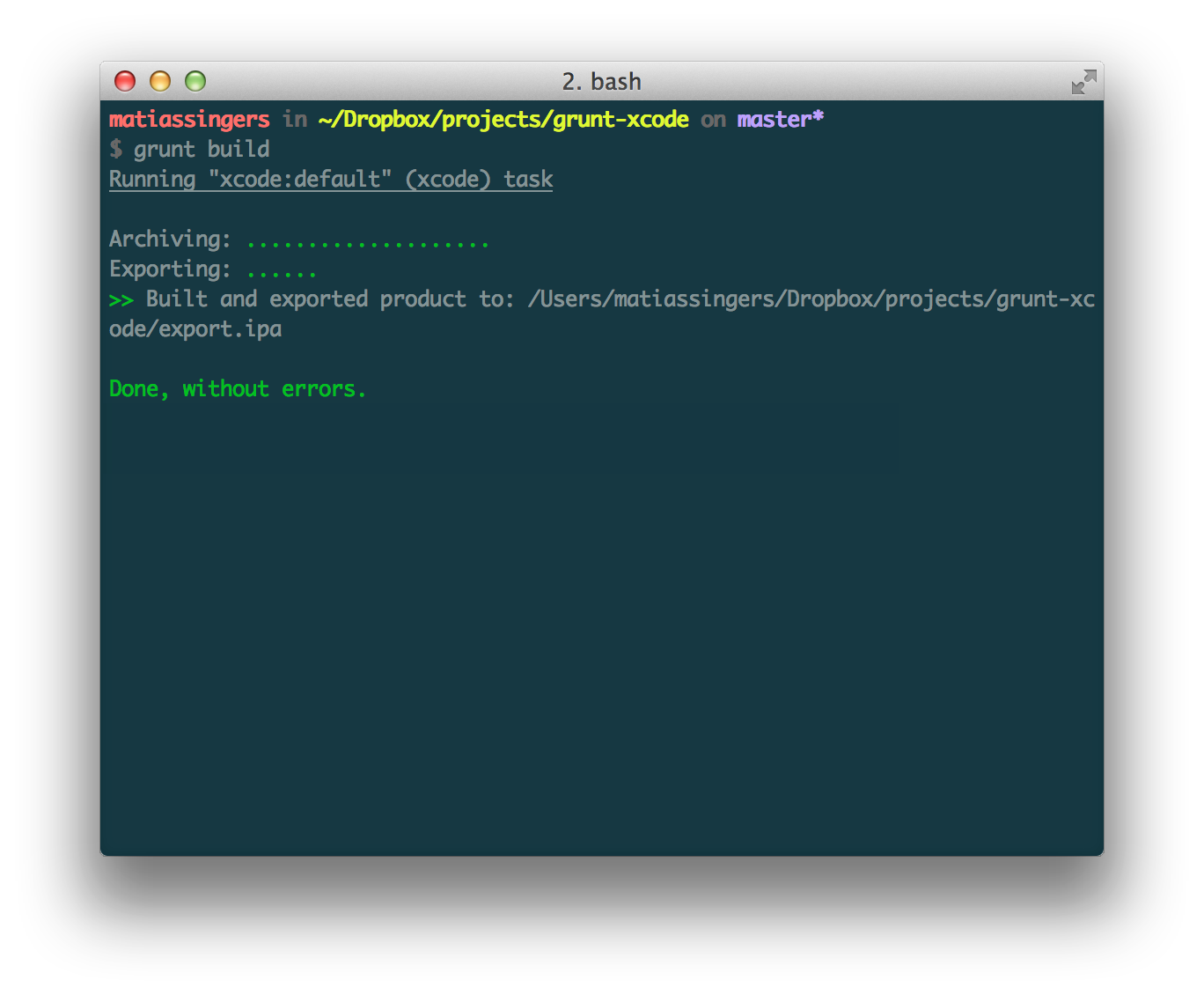
I started building the initial version of grunt-xcode around November last year. The primary reason for the project was that I was getting tired of manually having to do iOS builds for our clients - it needed to be a part of our Grunt build task.
I stumbled upon shenzhen which actually worked fairly well for me as a command-line tool, so I thought “hey let me just wrap this in JS”. That was probably not the wisest decision, but grunt-xcodev1 ended up sort of working for us (not so much for everybody else).
To be honest the code was quite ugly and I didn’t like the dependency on a RubyGem - it just didn’t feel right. I also started getting some bug reports on GitHub and email.
Rewrite
The primary goal of the rewrite was to remove the dependency on shenzhen and use the built-in xcodebuild tool instead.

{kind=link}
{kind=link}